
#1 线程介绍 ##1.1 启动线程
1.1.1 新建一个类继承Thread类,重写run()方法。
常规写法
class A extends Thread { @Override public void run() { System.out.println("......"); } public static void main(String[] args) { A a = new A(); a.start; // 启动线程 }} 匿名子类写法
class A { public static void main(String[] args) { Thread thread = new Thread() { @Override public void run() { System.out.println("......"); } }; thread.start(); }} 1.1.2 将逻辑定义在Runnable的run()方法中。
常规写法
class A implements Runnable{ @Override public void run() { System.out.println("......"); } public void main(String[] args) { A a = new A(); Thread thread = new Thread(a); thread.start(); }} 匿名内部类
class A { public static void main(String[] args) { Thread thread = new Thread(new Runnable() { @Override public void run() { System.out.println("......"); } }); thread.start(); }} Lambda表达式写法
class A { public static void main(String[] args) { Thread thread = new Thread(() -> { System.out.println("......"); }); thread.start(); }} ##1.2 启动线程方式的比较
Java单继承多实现,所以使用Runnable会更灵活,一般要使用Thread中的方法才会去继承Thread。
##1.3 启动线程的注意点 无论是继承重写run()方法还是实现Runnable接口中的run()方法,在run方法中只是写上你希望新开辟的线程为你做的逻辑。真正启动线程是需要主线程去调用新开辟的线程的start()方法才能启用线程去执行run()方法。
tips:启动JVM后不单只有一个主线程,还有垃圾回收,和内存管理等线程。
#2线程声明周期 ##2.1 Daemon 线程 主线程会从main()方法开始,直到main()方法结束后退出JVM。如果主线程中启动了额外的线程,默认会等待所有线程都执行完run()方法才退出JVM。如果有一个Thread被标记为Daemon线程,在所有非Daemon线程结束后Daemon线程才会结束并且退出JVM。 常用API:设置Daemon线程setDaemon(),判断Daemon是否为Daemon线程isDaemon();
tips:默认从Daemon线程产生的线程是也Daemon线程,所以在生成它的线程结束的时候也一并停止。
##2.2 线程状态图线程状态图以及常用API解释 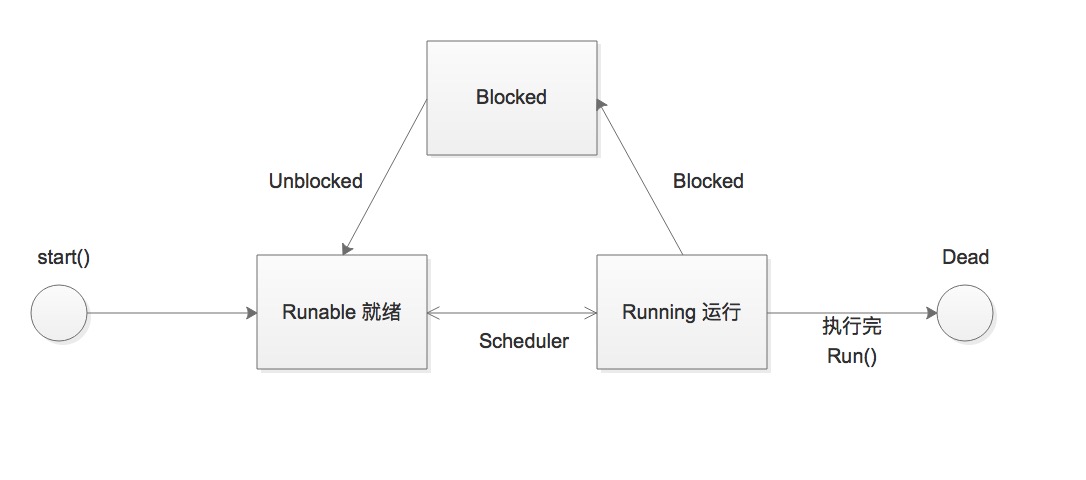
2.2.1 线程状态图
调用线程的start()方法后,一般有三种状态Runnable(就绪)、Running(运行)、Blocked(阻塞)。 当线程执行sart()方法后线程进入Runnable(状态)等待Scheduler(排班器)排入CPU执行,线程才会执行run()方法进入Running(运行)状态。 CPU同一个时间点上只会执行一个线程,但CPU会不断切换线程工作,这样使CPU实现了并行操作,这样使得线程看起来是同时执行的。
tips: 串行操作(按照执行顺序一个个来),并行操作(一会执行这,一会执行那),并发(需要多核CPU每个CPU处理分别处理一个操作)。
线程可以设置优先权通过setPriority()方法,默认5,范围1-10,数值越大,Scheduler(排版器)优先排入CPU执行。
Blocked(阻塞)一般有以下集中情况:
1 Thread.sleep() 线程休眠状态,此时线程是不会释放锁,当线程醒来(自然醒或者interrupt()唤醒)还是带着锁的,然后等到Scheduler排到他然后继续执行。
2 进入synchronized前竞争对象锁的阻断
3 调用线程wait()方法,线程释放对象锁进入对象的等待集合,当notify()通知他的时候,等待Scheduler排到他执行并再次去竞争锁。
4 等待输入/输出完成,读写大文件此时CPU是在阻塞在等待操作系统完成IO操作。
tips:当一个线程进入Blocked状态,让一个线程排入到CPU执行(成为Running状态),避免CPU空闲,是运用多线程改进效能的方式之一。
2.2.2 常用API-join() A线程正在运行,流程中使用join()操作将B线程加入,那么等到B线程执行完毕后再执行A线程。 join(xxxms)表示当插入的线程至多处理xxxms如果xxxms到了插入线程还没执行完毕,那么目前线程可继续执行原本工作。
2.2.3 停止线程
线程完成run方法后,就会进入Dead,已经调用过的start()方法的线程不能再次调用。 stop()方法,将不理会所设定的释放、取得锁流程,线程会直接释放所有已锁定的对象,这有可能使对象陷入无法预期的状态,除了stop()方法外,Thread的resume()、suspend()、destroy()等方法也已经Deprecated。
停止线程最好自行操作,让线程跑完应有流程而不是用stop()方法。
class A implements Runnable { private boolean flag = true; public void stop() { this.flag = false; } @Override public void run() { while (flag) { System.out.println("......"); } }} 2.2.4 ThreadGroup
每个线程都属于某个ThreadGroup,如在main()方法中产生一个线程那么就属于main线程群组。Thread.currentThread().getThreadGroup().getName();获得群组名。每个线程产生的时候都会归入某个线程群组中,可以指定行线程群组,不指定就归入产生该子线程的线程群组,一旦指定线程群组就无法更换。ThreadGroup的interrup、setMaxPriority()对群组中所有的线程都有作用。
当ThreadGroup中的线程发生异常,执行顺序如下:
1 ThreadGroup如果有父ThreadGroup那么调用父ThreadGroup的uncaughtException()方法。
2 看Thread中是否使用setUncaughtExceptionHandler()方法设定Thread.uncaughtExceptionHandler()实例,调用其uncaughtException()方法。
3 看下异常是否为ThreadDeath实力,是的话什么都不处理,不是的话打印堆栈。
可以重写ThreadGroup.uncaughtException以及Thread中的uncaughtException()这两个方法来实现自己所需要的异常控制。
2.2.5 synchronized 与 volatile
每个对象都会有个内部锁(Intrinsic Lock)或叫监控锁(Monitor Lock)。 任何线程要执行synchronized区块都必须先获得指定对象的锁。如果A线程取得对象锁开始执行synchronized区块,B线程也想执行synchronized区块,但因无法拿到对象锁而进入等待状态(Blocked),直到A线程释放锁(如执行完synchronized区块,或者A线程被wait()了),B线程才有机会去取得锁而执行synchronized区块。线程若因尝试执行synchronized区块而进入Blocked,在取得锁之后,会先进入Runnable状态,等待CPU的scheduler排入Running状态。
synchronized放置的几种位置
1 放在方法上(粗粒度)
public synchronized void add(Object object) { System.out.println("运行逻辑"); } 2 代码块(相对细粒度)
public void add(Object object) { // ... synchronized (this) { System.out.println("运行逻辑"); } // ... } 3 对于不是线程安全的类的方法
ArrayListarrayList = new ArrayList<>(); Thread thread = new Thread(() -> { // ... synchronized (arrayList) { System.out.println("运行逻辑"); } // ... });
4 使用Collections中的synchronizedCollection()、synchronizedList()、 synchronizedSet()、synchronizedMap()将传入的Collection、List、Set、Map、对象打包返回线程安全的对象
将上面的代码简化
Listlist = Collections.synchronizedList(new ArrayList<>()); // ... list.add(Integer.valueOf("....")); // ...
使用synchronized时,可以通过不同对象做为锁的来源实现更细粒度的控制。
class A{ private int data1 = 0; private int data2 = 0; private E e1; private E e2; public void doSome() { System.out.println("其他逻辑"); synchronized (e1) { data1++; } System.out.println("其他逻辑"); } public void doOther() { System.out.println("其他逻辑"); synchronized (e2) { data2++; } System.out.println("其他逻辑"); }}
此时doSome()和doOther()不会同时被两个以上的线程执行,并且data1与data2不同时出现在两个方法中,不会引发内存共享问题,并且此时不同方法提供不同对象做为锁的来源,这样不会导致一个线程在拿到锁之后执行doSome()中synchronized代码块,另一个线程在doOther()中的synchronized那发生获取锁的等待问题了。
Java中的synchronized提供可重入同步(Reentrant Synchronized),线程在获取某对象锁定后,在执行的过程中又要执行synchronized,此时取得锁对象是一个的话,那么可以直接执行。
死锁:当一个线程获取A对象锁之后需要获取B对象锁时,假设另一个线程获取B对象锁之后需要获取A对象锁,此时第一个线程因为要获取B对象锁进入Blocked,第二个线程要获取A对象锁也进入Blocked。
2.2.5 使用volatile
synchronized对所标志区块具有互斥性与可见性,互斥行:synchronized区块同一时间只有一个线程,可见性:线程离开synchronized区块后,另一个线程所接触到的就是上一个线程改变后的对象状态。
在Java中对可见性的要求,可以使用volatile达到变量范围。
正常情况下线程可以快取变量值,线程可以从共享内存中快取变量值放到自己的内存空间,然后将自己内存空间中快取的值输出出去。这可能导致当线程A快取一个值data之后,这个值data被线程B所改变,但此时A不会再取共享内存空间中拿到变化之后的值data而是直接拿自己内存空间中快取的值olddata输出出去。
此时可以在变量上声明volatile,表示变量不稳定,可能在多线程下存取,这保证了变量的可见性,当有线程变动了变量值,另一个线程可看到变化。被volatile声明的变量,不允许线程快取,变量值的存取一定是在共享内存中进行的。
volatiole保证的是单一变数的可见行,线程对变量的存取一定是在共享内存中的,不会在自己的内存空间中快取变量,线程对共享内存中变量的存取,另一个线程一定看得到。
2.2.6 等待与通知
wai() notify() notifyAll() 是Object定义的方法,通过这三个方法控制线程释放对象的锁,或者通知线程参与锁的竞争。
线程进入synchronized范围前,需要先获得对象的锁。执行synchronozed范围的程序代码期间,若调用锁定对象的wait()方法,线程会释放对象的锁,进入此对象的等待集合(WaitSet)而处于Blocked,此时其他线程可以竞争对象锁,拿到锁之后执行synchronized代码块。
tips: 调用wait()方法的时候必须锁定该对象。
放在等待集合的线程不参与CPU排班,wait()可以指定时间,时间到之后线程进入排班,如果指定时间为0或者不指定,则线程持续等待,知道被中断(interrupt())或是notify()可以参与排班。
tips: 因为wait()后的线程处于Blocked不是Runnable所以是不能进入CPU排班
被竞争锁定的对象调用notify()时,会从对象等待集合中随机通知一个线程加入排班,再次执行synchronized前,被通知的线程会和其他线程功能竞争对象锁;如果调用notifyAll(),所以等待集合中的线程都会参与排班,这些线程会与其他线程共同竞争对象锁。线程调用wait()方法进入等待当时间到或notify(),进入排班并取得对象锁之后再从调用wait()处开始执行。notifyAll()同理
##2.3 并行API
2.3.1 java.util.concurrent包中的Lock、ReadWriteLock、Condition
Lock:
class A { private Lock lock = new ReentrantLock(); // 声明类全局变量lock 一个对象一个锁 // 类似于一个对象一个synchronized public void doSome() { lock.lock(); // 上锁 try { // ... } finally { lock.unlock(); // 一定要释放锁 并且为了释放锁成功要放在finally中 } }} ReentrantLock可以达到synchronized的作用,如果已经有线程取得Lock对象锁定,尝试再次锁定同一Lock对象是可以的。锁定Lock对象可以调用其lock()方法,只有取得Look对象的锁定的线程,才可以往下执行,接触锁定调用Lock对象的unlock方法。
Lock接口还定义了tryLock()方法,如果线程调用tryLock()可以取得锁定那么返回true,若无法取得锁定不会发生阻断而是返回false。Lock接口还有isHeldByCurrentThread()方法返回true,false。
ReadWriteLock:
ReentrantReadWriteLock.ReadLock操作lock()方法时,若没有任何ReentrantReadWriteLock.WriteLock调用lock()方法,也就是没有任何写入锁定的时候,就可以取得读取锁定(读取锁可以同时被多个线程拿到)。 ReentrantReadWriteLock.WriteLock调用lock()方法时,若没有任何 ReentrantReadWriteLock.ReadLock或ReentrantReadWriteLock.WriteLock调用过lock()方法,也就是没有任何读取或者写入锁定的时,才可以取得写入锁。
读锁可多线程,在获取读锁之前没有任何写锁才能获取读锁。 在没有任何读锁和写锁的时候才能获取写锁。使用读写锁使得读写操作分离,增加读取效率。
class A{ private ReadWriteLock lock = new ReentrantReadWriteLock(); private E data; public E get() { // lock.readLock() 返回 ReentrantReadWriteLock.ReadLock// ReentrantReadWriteLock.ReadLock readLock = (ReentrantReadWriteLock.ReadLock) lock.readLock(); lock.readLock().lock(); try { return data; } finally { lock.readLock().unlock(); } } public void set(E e) { // lock.writeLock() 返回 ReentrantReadWriteLock.WriteLock// ReentrantReadWriteLock.WriteLock writeLock = (ReentrantReadWriteLock.WriteLock) lock.writeLock(); lock.writeLock().lock(); try { this.data = e; } finally { lock.writeLock().unlock(); } }}
StampedLock:
ReadWriteLock在没有任何读取或写入锁定时,才可以取得写入锁定,这可以用于实现悲观读取(Pessimistic Reading)。
然而当读取线程多,写入线程少的时候,使用ReadWriteLock可能使得写线程处于Starvation(饥饿)状态,因为写入锁可能迟迟无法竞争到锁,而处于等待状态。此时JDK8中增加了StampedLock类,可支持乐观读取(Optimistic Reading),也就是当读取线程多,写入线程少,可以乐观的认为写入与读取同时发生的机会较少。因此不悲观地使用完全的读取锁定,程序可以查看数据读取之后,是否遭到写入线程的变更,再采取后续措施(重新读取变更后的数据,或者抛出例外)。
class A{ private StampedLock lock = new StampedLock(); private E data; public E get() { long stamp = lock.tryOptimisticRead(); // 试着乐观读取锁(不会真正执行读取锁定) // 1 返回stamp给validate用 2 如果已经有排他锁返回0 E res = data; if (!lock.validate(stamp)) { // 查询是否有排他所的锁定 1 没有排他锁返回true 2 stamp是0的话返回false // 3 stamp表示当前已持有的锁返回true 4 戳记stamp被其他排他锁获取返回false stamp = lock.readLock(); // 使用readLock()做真正的读取锁定 try { res = data; // 在锁定的情况下更新局部变量 } finally { lock.unlockRead(stamp); // 解除读取锁定 } } return res; // 没有其他排他锁直接返回变量 } public void set(E e) { long stamp = lock.writeLock(); try { this.data = e; } finally { lock.unlockWrite(stamp); } }}
tips: 在validate()之后发生写入而返回结果不一致是有可能的,如果此时需要保证数据一致性,那么应该使用悲观读取。
Condition:
Condition接口用来搭配Lock,实现与Object的wait(),notify(),notifyAll()相同的效果。分别是Condition的await(),signal(),signalAll()。 当多线程操作统一对象的时候,Object的wait()会让不同类型的线程多在此对象的等待集合中等待,当notify()通知的时候是随机通知的。但使用Conditon我们可以创建多个Condition对象,当使用await()方法那么就可以到指定的Condition的等待集合中,通知的时候也可以到指定的Condition对象的等待集合中通知。
class A{ private Lock lock = new ReentrantLock(); private Condition condition1 = lock.newCondition(); private Condition condition2 = lock.newCondition();}
Executor:
Runnable用来定义可执行流程与可使用数据,Thread用来执行Runnable。将Runnable指定给Thread创建用,并调用start()方法。 java.util.concurrent.Executor接口,出现在JDK1.5,目的是将Runnable的指定与实际如何执行分离。
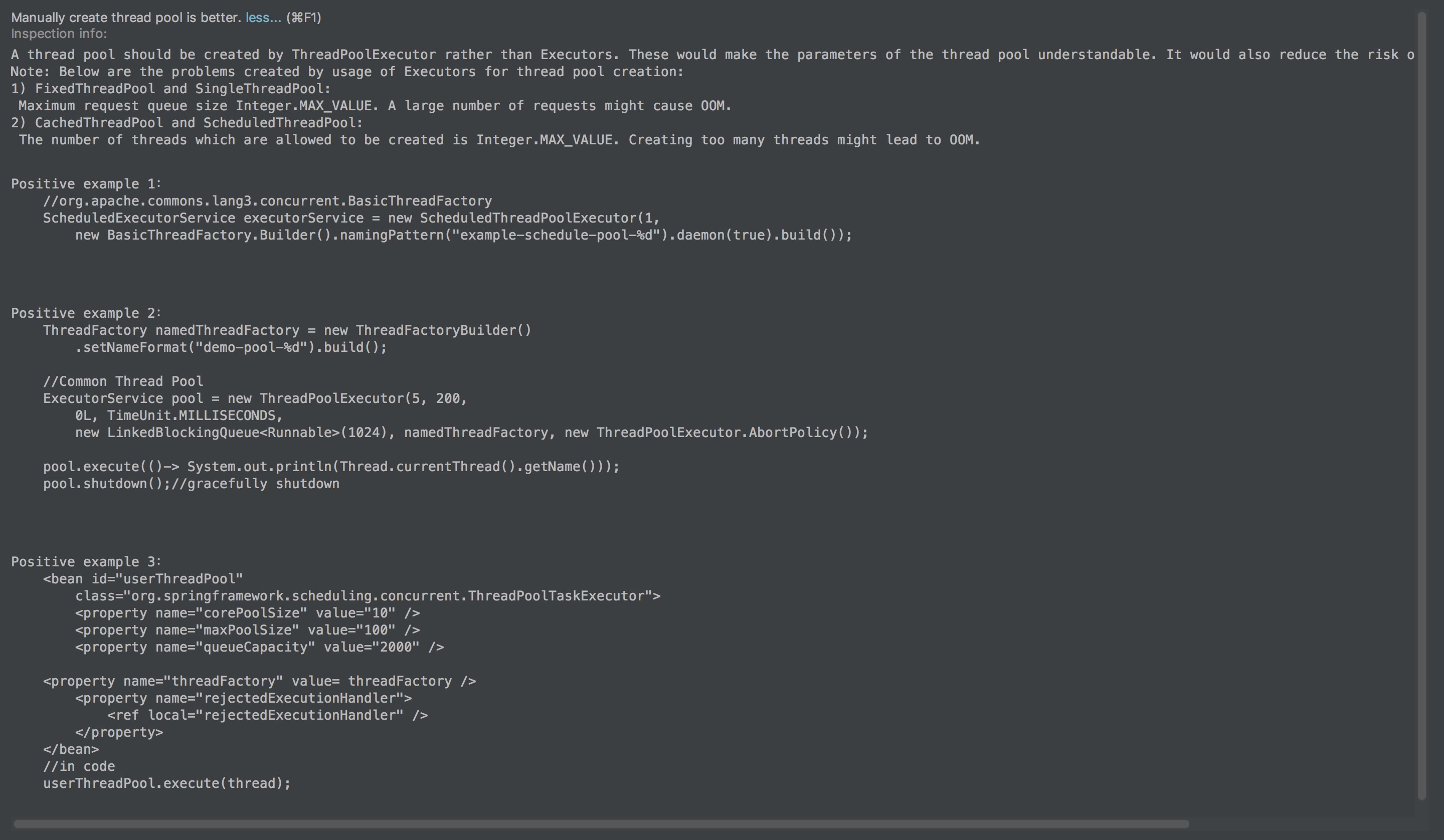
Java线程池的操作方法定义在Executor的子接口ExecutorService(java.util.concurrent.ExecutorService)中,由抽象类AbstractExecutor实现,如果需要使用线程池功能的话可以使用其子类java.util.concurrent.ThreadPoolExecutor,ThreadPoolExecutor有多种构造方法。
class A { public void doSome(Executor executor) { System.out.println("执行逻辑"); } public static void main(String[] args) { // 使用newFixedThreadPool创建线程的时候指定线程数量// Executors.newFixedThreadPool(5); // java.util.concurrent.Executors 的 newCachedThreadPool() 创建ThreadPoolExecutor // 使用上面的方法创建线程池会在必要的时候建立,Runnable可能执行在新建的线程上,也可能在重复利用的线程中 ExecutorService executorService = Executors.newCachedThreadPool(); new A().doSome(executorService); // shutdown()方法会在指定执行的Runnable都完成后将ExecutorService(此处是ThreadPoolExecutor)关闭 executorService.shutdown(); }} IDEA不推荐上面两种创建方法理由如图。
Future与Callable:
ExecutorService中的submit(),invokeAll(),invokeAny()中用到了java.util.concurrent.Future以及Callable。
Future:将想执行的工作交给Future,Future会使用另外一个线程来工作,此时你可以去忙别的事情,过些时候再调用Future.get()方法取得结果,如果结果产生了,get()直接返回结果,否则进入阻断状态直到结果返回。get()还可以指定等待结果的时间,若时间到还未产生结果则抛出java.util.concurrent.TimeoutException,也可以使用Future的isDone()方法查看是否有结果产生。
Future经常与Callable搭配使用,Callable与Runnable相似但有两点不同Runnable的run()方法无法产生返回值,无法抛出收检异常(如Thread.sleep的异常一定要在run()中try catch。FutureTask创建的时候可以接受Runnable或者Cabble两种。
class A { static String getStr() throws Exception { Thread.sleep(5000); return "Lambda表达式的测试方法执行完成"; } public static void main(String[] args) throws Exception{ FutureTask futureTask = new FutureTask (new Callable () { @Override public String call() throws Exception { Thread.sleep(8000); return "内部匿名类的测试方法执行完成"; } }); FutureTask futureTask2 = new FutureTask (A::getStr); // FutureTask也实现了Runnable接口所以也可以给Thread创建实力用 new Thread(futureTask).start(); new Thread(futureTask2).start(); while (!(futureTask.isDone() && futureTask2.isDone())) { System.out.println("我去干其他事情了"); } System.out.println(">>>>两个FutureTask都完成了" + "FutureTask1:" + futureTask.get() + "FutureTask2:" + futureTask2.get()); }} 使用线程池的submit方法返回Future让我稍后取得结果。
class A { static String setChicken(int num) throws InterruptedException { // 用线程休眠10秒表示 老板再做30份烤鸡 Thread.sleep(5000); return "老板做了" + num + "只烤鸡"; } public static void main(String[] args) { ExecutorService service = Executors.newCachedThreadPool(); System.out.println("老板我要30份烤鸡"); // ExecutorService的submit()方法接口Callable对象,调用后返回Future对象 // 为了让你在稍后可以取得运算结果 // 这边做30个烤鸭比上面做30个烤鸡快,上面是Thread.start()后执行Future,Future使用 // 单个新线程来做30个烤鸡,但这边使用线程池,相当于好多个线程一起做30个烤鸡 Future futureTask = service.submit(() -> setChicken(30)); while (!futureTask.isDone()) { System.out.println("我去干其他的了"); } System.out.println("老板的30份烤鸡好了"); }} ScheduledThreadPoolExecutor:
ScheduledExecutorService的实现类ScheduledThreadPoolExecutor并且继承ThreadPoolExecutor,具有线程池和排与线程排程功能。 可以使用Executors。
class A { public static void main(String[] args) { // 单个线程排程 ScheduledExecutorService service = Executors.newSingleThreadScheduledExecutor(); service.scheduleWithFixedDelay(() -> { System.out.println(new Date()); try { Thread.sleep(2000); // 假设这个工作会进行两秒 } catch (InterruptedException e) { e.printStackTrace(); } }, 2000, 1000, TimeUnit.MILLISECONDS); // 线程进入后等待2S开始排程工作 // 上一个线程结束后等待1S继续下个线程 service.scheduleAtFixedRate(() -> { System.out.println(new Date()); try { Thread.sleep(2000); // 假设这个工作会进行两秒 } catch (InterruptedException e) { e.printStackTrace(); } }, 2000, 1000, TimeUnit.MILLISECONDS); // 线程进入后等待2S开始排程工作 // 上一个线程结束后等待1S继续下个线程,如果下个线程在1S后没完成,那么等线程完成工作后直接执行 // 下一个线程 }} ForkJoinPool:
Future的一个实现类java.util.concurrent.ForkJoinTask及其子类有ExecutorService另一个实现类java.util.concurrent.ForkJoinPool有关,他们主要用来解决(Divide and Conquer) 分而治之的问题。 ForkJoinTask在ForkJoinPool管理的时候执行fork()方法,则会以另外一个线程来执行他,调用join()取得结果,无结果则等待至结果返回。一般使用ForkJoinTask的子类RecursiveTask和RecursiveAction, 用类继承两个的其中一个,有返回值用RecursiveTask,没返回值用 RecursiveAction,调用的时候使用他们的compute方法。
class A extends RecursiveTask{ private long n; public A(long n) { this.n = n; } @Override protected Long compute() { // 操作compute()方法 将子任务的分解和求解放到compute()中 if (n <= 20) { // 避免分解出过多的子任务造成负担。 return usualSolve(n); // 小于20的不分解,直接循环运算 } // 分解出n-1子任务请ForkJoinPool分配线程来执行 ForkJoinTask subTask = new A(n - 1).fork(); // 分解n-2子任务并且直接运行 + 取得子任务执行结果。 return new A(n - 2).compute() + subTask.join(); } private long usualSolve(long n) { if (n <= 1) { return n; } return usualSolve(n - 1) + usualSolve(n - 2); } public static void main(String[] args) { A a = new A(45); ForkJoinPool pool = new ForkJoinPool(); // 所有ForkJoinTask实力的compute()方法执行完之后,ForkJoinPool就会关闭 System.out.println(pool.invoke(a)); // 开始分而治之 }}